Building a Location-First Learning Agent to Explore Context, Memory, and Consciousness
This explores the idea that recognition comes more from place, context, and repeated reinforcement than detached labels, using an inspectable Python CLI agent that learns locations from sensor observations and stores state plainly. It evolves from simple grayscale location memory into richer, modality-neutral location and concept structures, with a roadmap toward broader memory processes like activation, replay, resurfacing, and reconsolidation.
Maybe recognition is less about detached labels than it is about where something is, what surrounds it, and how that context gets reinforced. That is what pushed me to build this repo. I wanted a smaller problem that still felt close to the thing I cared about. The question that kept pulling me back was whether location and context are a big part of knowing something at all, and whether they help make object recognition faster and more grounded.
That led me to build a small location-first learning agent. Right now it is a Python CLI project that learns from scalar observations and simple file-backed sensor inputs, stores what it learns in plain JSON and JSONL, and keeps the whole state inspectable. It is not a finished cognitive architecture, and it does not pretend to be one. What it gives me instead is a controlled place to test a very specific idea: maybe recognition does not start with detached labels, maybe it starts with where something is, what surrounds it, and how that context gets reinforced over time.
I also made a deliberate structural choice early on. I started out working with Thousand Brains Project Monty, but I split this work into a separate repo because I wanted a simpler environment where I could move directly on the parts I was most interested in. I did not want to spend my time threading a new experiment through a larger existing system before I understood the experiment itself.
Why I started with location
There are plenty of ways to make a toy agent look smarter than it is. I was more interested in making one that was inspectable. That meant I needed a narrow problem, a tight loop, and data structures I could read without translation.
So the first version of this project was almost stubbornly small. It learned grayscale observations mapped to location labels, persisted them across sessions, and logged each interaction. That sounds minimal, and it is, but it gave me a starting point for a question I still care about: if an agent repeatedly encounters a signal in a place-like context, what should it actually remember, and what should count as the identity of that memory?
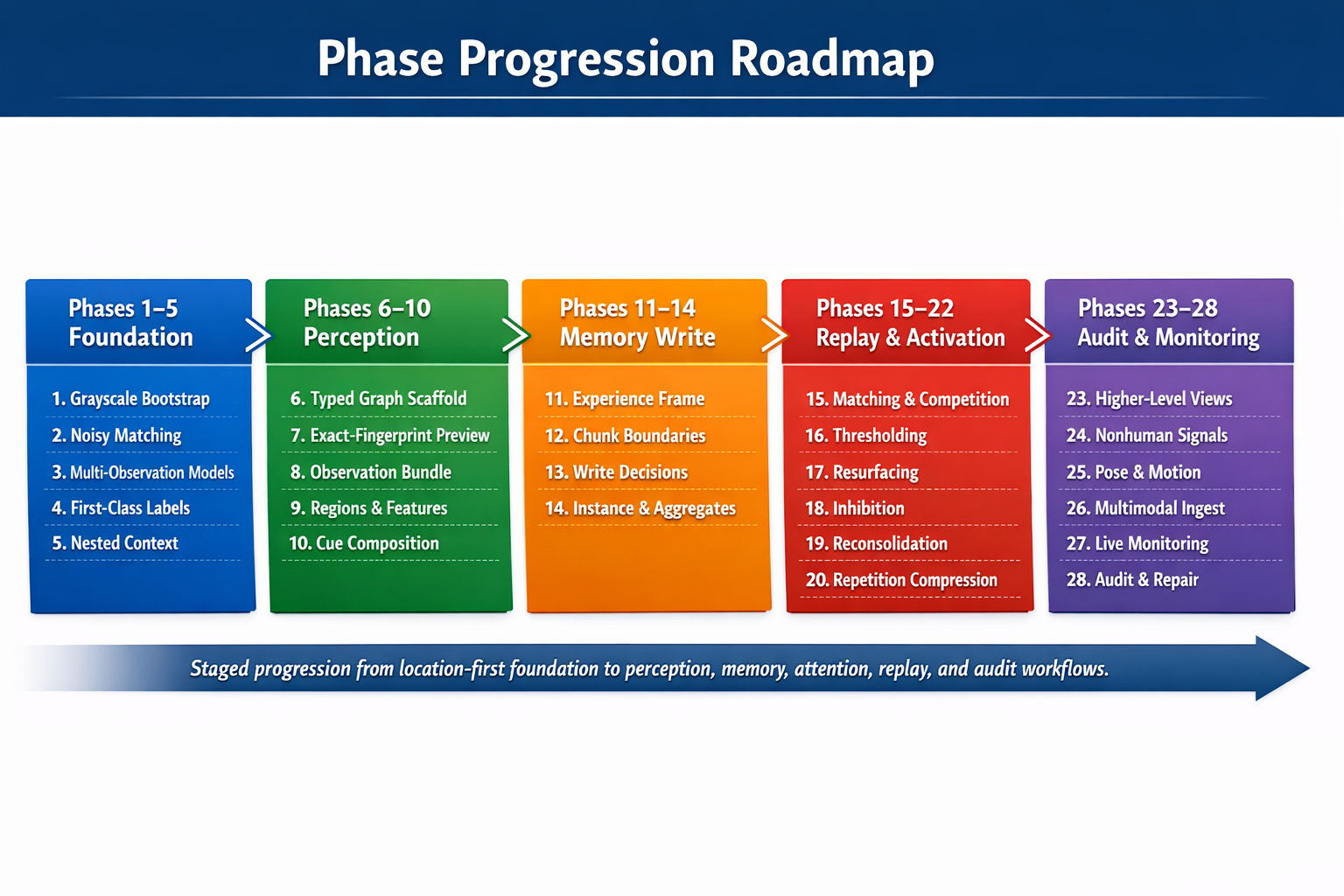
The repo has moved through a few clear phases since then:
-
Phase 1 bootstrapped exact-match grayscale memory with persistence and append-only logging.
-
Phase 2 added noisy scalar matching and confidence thresholds.
-
Phase 3 merged repeated observations into location models instead of treating every value as a separate record.
-
Phase 4, the current phase, introduces first-class labels, aliases, rename history, sensor bindings, and provenance-aware evidence records.
That progression matters to me because it shows the shape of the project. I am not trying to jump straight from nothing to a full theory of mind. I am trying to build up a memory system that stays small enough to reason about while it gets more structured.
What the current project actually does
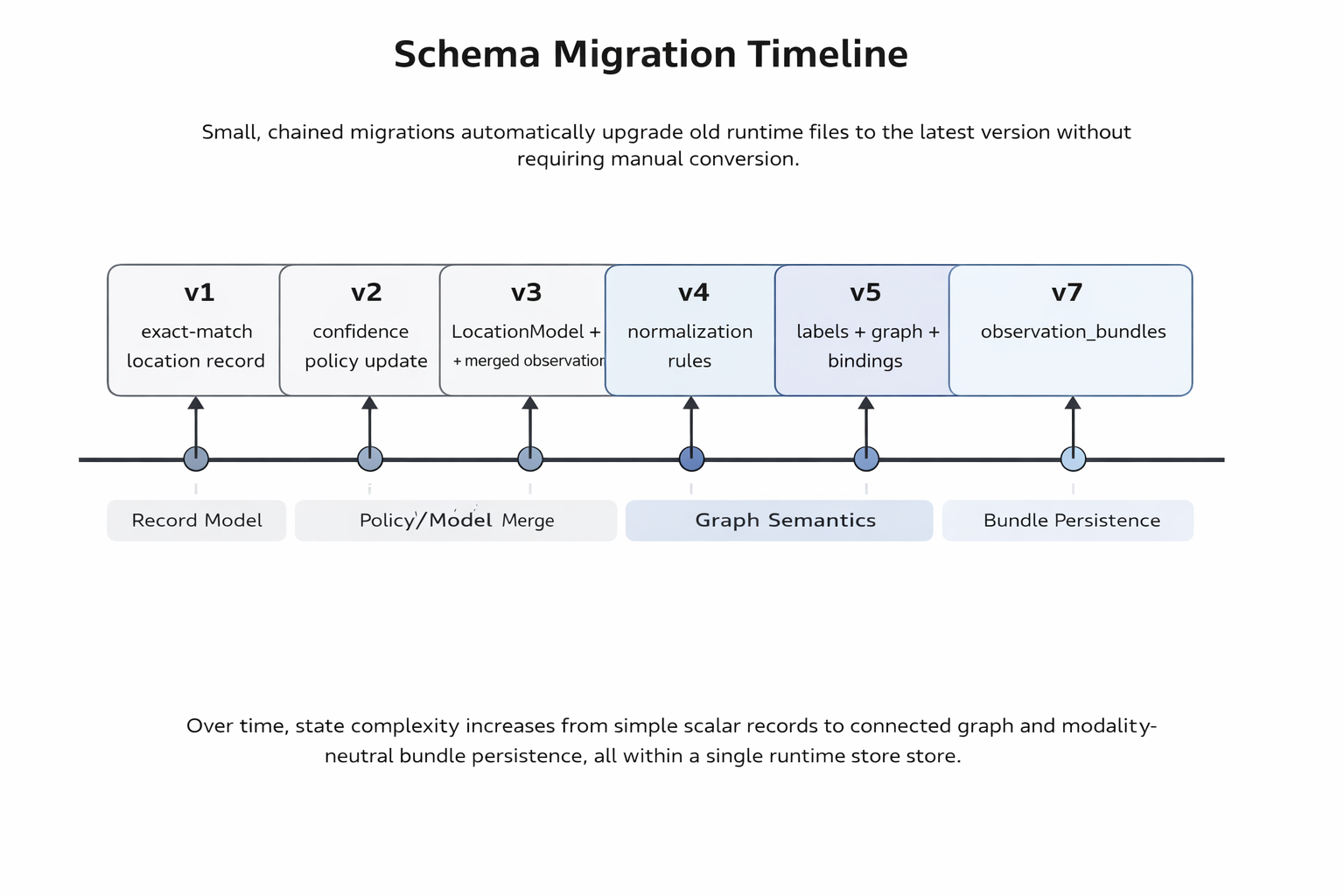
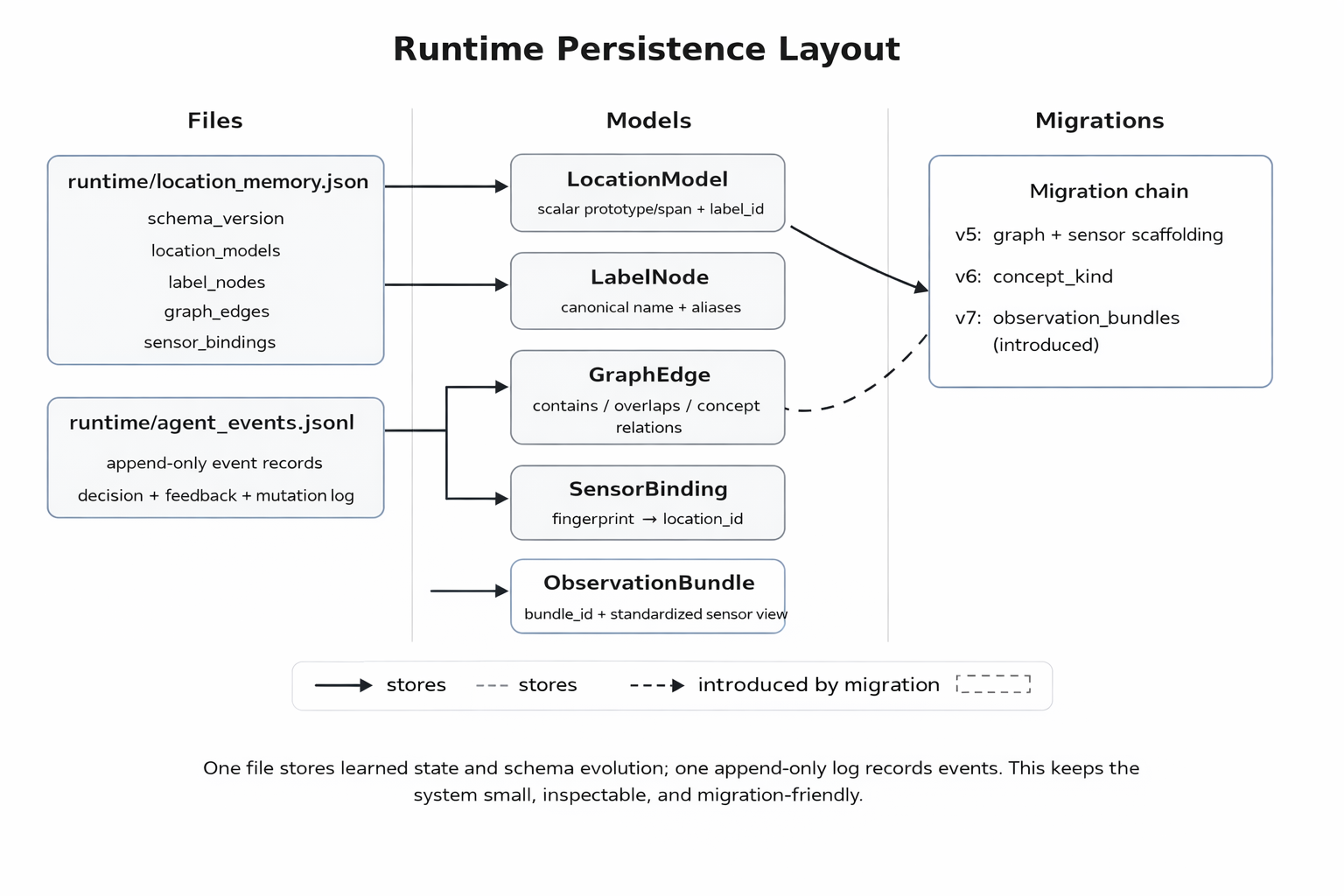
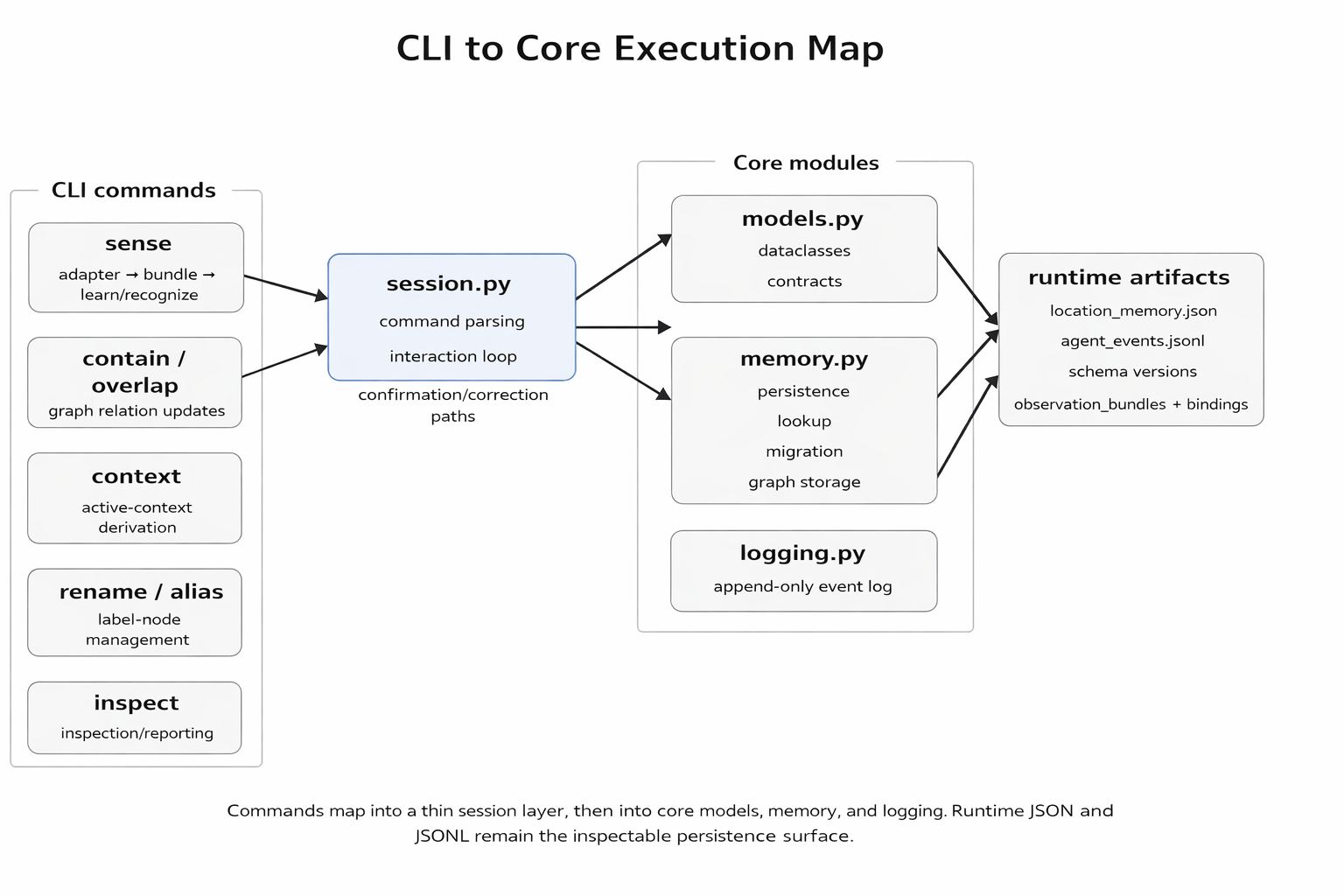
At the moment, this project is a stdlib-only Python CLI with no external packages required. I can run it, enter a grayscale value between 0.0 and 1.0, and either teach it a new location label or confirm a guessed one. It stores learned state in runtime/location_memory.json and appends interaction events to runtime/agent_events.jsonl.
That by itself would be a modest memory toy, but the current phase adds a few pieces that made the project feel more meaningful to me.
First, the system no longer treats the label as the identity. A location model now points to a label_id, and the label itself lives as a separate node with a canonical name, aliases, and rename history. That sounds like a small refactor, but it changed the shape of the project. Once I separated the thing being remembered from the latest name attached to it, a lot of awkward cases stopped feeling awkward. A label could change without pretending the location itself had changed. An alias could be useful without becoming a duplicate. A wrong guess could be corrected without discarding the old path through the system.
Second, scalar matching is not just nearest-prototype matching anymore. If the same location is confirmed across a wider range of observations, the system treats that inclusive span as learned territory. In practical terms, if I teach one location at 0.10 and 0.30, a later value like 0.28 can default to that same place unless conflicting evidence shows up. I like this because it feels closer to how a memory should broaden, not just average.
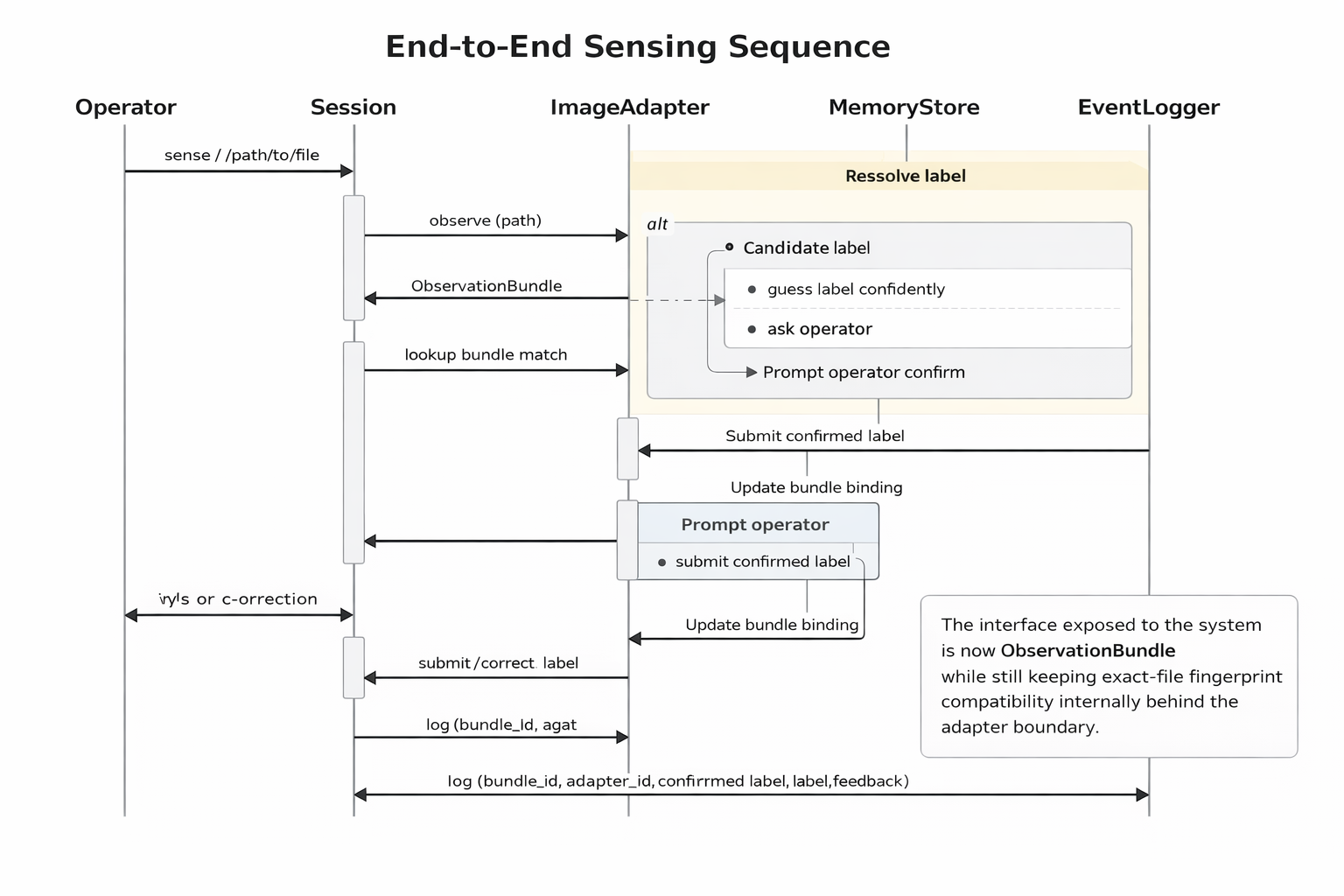
Third, the current phase adds a sensor preview through sense /path/to/file. This lets the agent learn or recognize a file-backed input and bind it to a location. The important limitation is that it does this through exact file fingerprinting. It hashes the file contents, stores the fingerprint, and re-recognizes that exact input later. That is useful as a stepping stone, but it is not the final perception model I want. I have been careful in the repo docs to describe it as a temporary preview, because I do not want a convenient shortcut to quietly become the architecture.
The design decision that mattered most: identity is not the same thing as a name
The strongest technical decision in the current codebase is also the one that feels most conceptually important to me: label identity should be separate from the human-readable name.
In earlier versions, the mapping between a learned signal and a label was much flatter. That worked for bootstrapping, but it also made the memory feel brittle. If the name changed, the memory structure had to behave as if the thing itself changed. If I wanted synonyms or better naming later, I was really just patching a string field.
Phase 4 changes that by introducing LabelNode and storing label ownership through label_id. The location model keeps its own identity. The label keeps its naming history. Aliases stay attached to the same node. Wrong-guess corrections can rename the canonical label while preserving the old name as an alias. That is a cleaner technical model, but it also gets closer to the question that motivated the project in the first place. A remembered thing should not vanish just because I describe it better later.
This also made the inspectability better. The inspect command can now surface canonical label, aliases, label id, prototype, spread, observation count, and rename count in one place. The runtime schema also carries sensor_bindings, graph_edges, concept_nodes, and evidence_records, even though some of that is still scaffolding for later phases. I like that the state can be read directly. I can see what the agent knows, why it knows it, and which parts are still placeholders for future work.
The second big decision: keep the sensor preview useful, but refuse to confuse it with perception
One of the easier traps in projects like this is letting a convenient shortcut turn into a story about capability. The current image sensing path is useful because it gives me a way to test the learning loop with actual files and a repo-local media pack. The repo now includes generated-local Phase 4 fixtures, a media catalog, and scenario manifests so that part of the project stays deterministic and testable.
That part is real, and I think it is valuable.
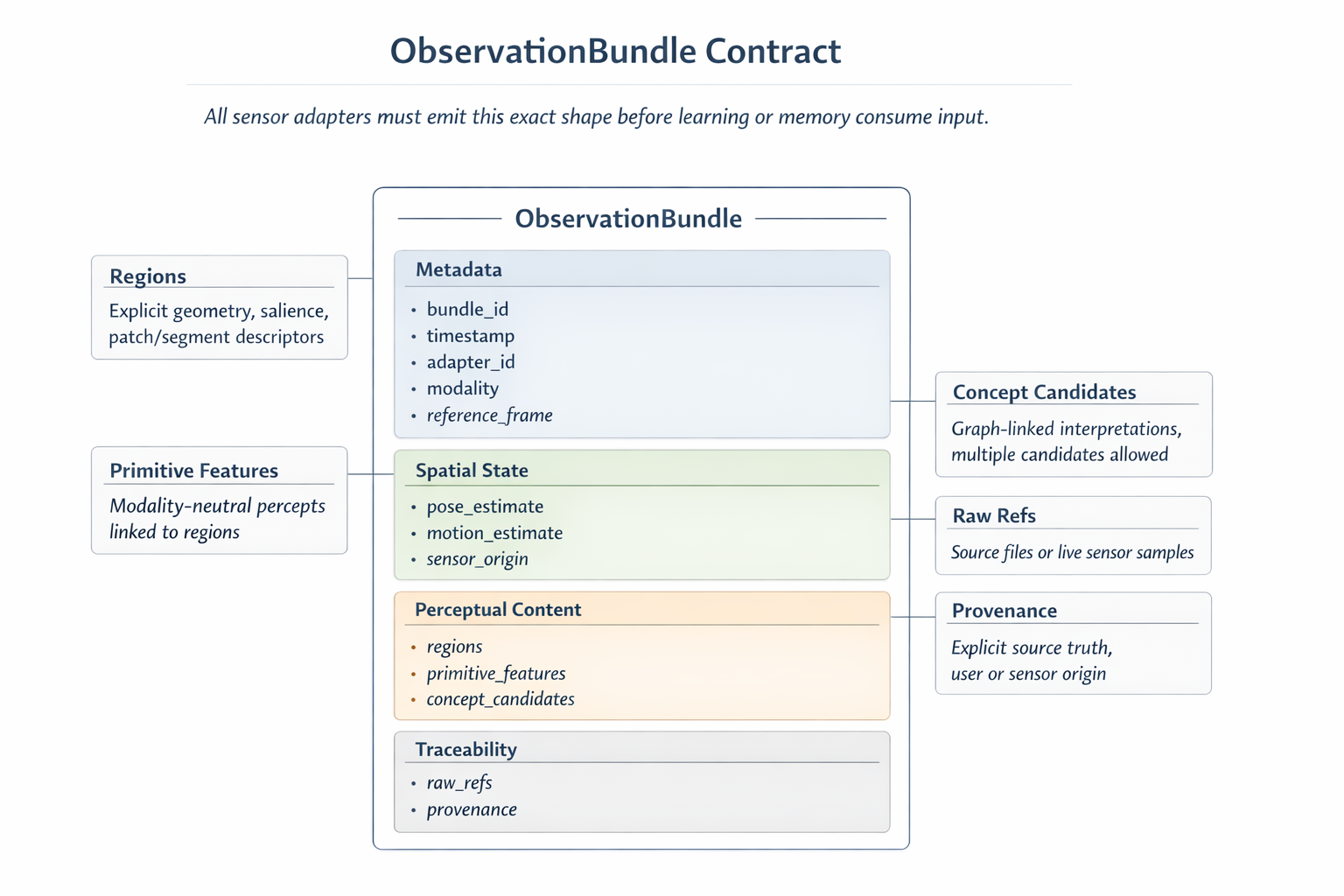
What is not real yet is content-based perception. The system is not identifying rooms from visual structure, learned features, or scene composition. It is binding exact file fingerprints. The docs are explicit that later phases should move toward an ObservationBundle contract, region attention, primitive percepts, cue composition, and eventually a broader memory-and-attention engine. I think that distinction matters, because otherwise it would be easy to oversell what is happening now.
For the article, I want to be clear about both sides of that. The current preview is not nothing. It gave me a practical way to test location binding with deterministic image fixtures. But it also is not the end state, and I do not want to talk about it as if it already solves perception.
Why I kept the implementation plain
This project is intentionally plain in a few ways. It is stdlib-only. The CLI is synchronous and line-oriented. Persistence is single-writer JSON and JSONL. None of that is glamorous, and I am fine with that.
The benefit is that the moving pieces stay readable. The memory store is a JSON document. The event log is append-only. The tests say what the current phase is expected to do. The decisions file says why I changed the model when I did. Even the limitations are documented pretty directly, including the fact that Phase 4 still has pending manual acceptance even though the automated suite passes.
That simplicity fits the purpose of the project. I am not trying to hide the structure behind a polished interface yet. I am trying to make the structure legible enough that I can tell when a design choice actually helps.
What is implemented, and what is still only a roadmap
This is where I think a lot of projects get muddy, so I want to keep it clean.
-
persistent scalar learning with confidence and span-aware matching
-
first-class labels with aliases and rename history
-
exact-file sensor binding for a temporary image-preview path
-
provenance-aware evidence records restricted to user or sensor sources
-
repo-local fixture images, scenario manifests, and validation checks
Documented for later, but not implemented yet:
-
ObservationBundle -
ExperienceFrame -
MemoryUnit -
activation competition
-
replay
-
resurfacing
-
reconsolidation
-
richer body-relative and multimodal context
I have already written those future concepts into the roadmap because I want a stable direction for the project, but I do not want to collapse the distinction between "planned" and "running." Right now this is still a location-first learning system with a broader cognitive direction, not a finished memory engine.
What I learned from building it this way
The main thing I learned is that narrowing the scope did not make the project less interesting. It made the interesting parts easier to see.
Separating label identity from naming made the whole memory story cleaner. Treating repeated confirmations as reinforcement rather than duplication made the learned state feel more coherent. Keeping the sensor preview deliberately temporary forced me to write down what I actually mean by perception instead of hiding behind a convenient shortcut.
I also learned that inspectability changes how I think about progress. A project like this can sound more advanced than it is if I only describe the aspiration. The files, tests, schema versions, and event logs keep me honest. They give me something concrete to evaluate, and they make it easier to notice when a new feature is really just a patch over a muddled model.
Where I want to take it next
The project is still a work in progress, and I plan to keep iterating and testing it in my free time. The next steps in the repo point toward richer context, typed concept scaffolding, and eventually a more general memory-and-attention layer, but I am still treating the current implementation as the thing that has to earn the next layer.
That is probably the clearest way I can describe the project right now. I started it because I wanted a personal space to test ideas about consciousness. I narrowed it to location and context because that felt like something I could actually build and inspect. Now I am using that smaller system to figure out which ideas survive contact with code.
I will post more about it after I have a better sense of what it can and cannot do. If you have thoughts about location, context, or memory design, I would be interested to hear them. The project is still early enough that those conversations can still influence how I shape the next layers.
If you want to follow along you can find the repo here:
-
GitHub: github.com/zsturman
-
LinkedIn: linkedin.com/in/zacharysturman
-
Portfolio: zachary-sturman.com
-
Email: Zasturman@gmail.com
Keep reading
More from the portfolio
Related and recent articles
How I Use Notion to Ingest, Organize, and Track My Projects
This Notion setup is a guided project intake workflow rather than a simple notes system: each project starts from a template, highlights the highest-priority next step, and builds toward execution, portfolio readiness, and future automation. By checking key setup steps automatically and separating projects, tasks, assets, resources, and milestones into linked systems, it reduces friction and makes the workflow easier to manage as it scales.
April 1, 2026
Automating Linear From Notion
A bidirectional sync engine that keeps Notion and Linear aligned by normalizing their data into shared models, reconciling meaningful changes, and preserving relationships and identity across systems.
March 25, 2026
Projects connected to this article

Train of Thought Agent
I’m using this project to test whether memory and recognition should begin with location and context instead of detached labels. Right now it is a plain, inspectable learning system that can take simple observations and file-backed sensor inputs, learn names, keep aliases and nested context straight, and show its state instead of hiding it. That makes it useful less as a finished product and more as a research tool and portfolio case study for technically curious readers, AI builders, and engineers who care about systems they can trace, correct, and inspect. What makes it distinct is the combination of restraint and ambition: it stays grounded in user or sensor evidence, it is careful not to pretend temporary sensing shortcuts are full perception, and it keeps a clear path toward a broader memory-and-attention engine. There is still real uncertainty around the final product shape, because the long-range memory system is mostly roadmap while the current learning loop is real and working. The overall character is thoughtful, methodical, and a little provisional on purpose, more like a careful research notebook than a polished AI launch.
My Notion Pipeline
An automated project and portfolio workflow that uses Notion as the central source of truth for capturing, organizing, maintaining, and publishing work across its full lifecycle. What began as a folder-based system built on local files and .project.json evolved into a relational Notion workspace that connects project metadata, work logs, tasks, milestones, media, and documentation in one structured environment. Inside Notion, the system uses formulas, required-action logic, severity scoring, and visual workflow signals to make project readiness measurable and easier to manage. That structure reduces duplicate entry, improves documentation quality, and keeps projects consistently maintained as they move from idea to execution to presentation. When project data reaches the right state, n8n detects qualifying changes and assembles portfolio-ready JSON, which is then sent into a Python-based build pipeline that prepares content and media for a static portfolio site. Linear supports issue tracking, GitHub stores code and optimized assets, and Firebase Hosting serves the finished site. The result is a connected operating system for project operations and portfolio publishing: one that keeps documentation, execution, and presentation aligned with the real state of the work over time.
Bias Detecting AI
This is a practical evaluation tool I’m using to check whether language models treat similar people differently when the only thing that changes is a demographic signal. It brings together structured bias tests, side by side model comparison, detailed result review, and prompt rewriting, so I can look at fairness as something concrete and inspectable rather than abstract. The clearest audience is people choosing, auditing, or shaping models before those models are used in higher-stakes workflows. That could be product teams, AI governance work, research, operations, hiring teams, or admissions related review. What makes it useful is that it does not stop at scoring. It also helps me clean up prompts, reuse safer templates, and recommend models based on the kind of task I actually care about. A few things still feel open, and I think that is worth saying plainly. This reads more like a focused internal evaluation desk than a broad shared platform, and more like an early, working system than a fully polished brand experience. The character is careful, measured, plainspoken, and a little austere, which fits a product that is really about close comparison and accountable judgment.

Episodic Memory Agent
An event-segmented episodic memory agent designed to simulate how an intelligent system perceives, interprets, and organizes experience over time. The architecture centers on a strict cognitive loop—resolving location, identifying entities, detecting change—and freezing those moments into structured episodes. Built with swappable modules, strict invariants, and full logging, the system prioritizes learning over hardcoded assumptions, user-defined semantics over predefined categories, and reproducible behavior over opaque heuristics.